This week we'll talk a little bit about NLP, or Natural Language Processing.
ChatGPT took the world by storm, and now we have Llama, Claude, Gemini, whatever. What are they and where did they come from? I was obsessed with watching the progression of AI and Deep Learning around 2016 when Google first released TensorFlow, back when it was still only cool in the tech world, but now you'd probably have to hide under a rock to entirely avoid hearing about it.
Word2Vec
We'll start at Word2Vec since this is my first favorite machine learning algorithm. Let's borrow this image from School of Informatics at the University of Edinburgh:
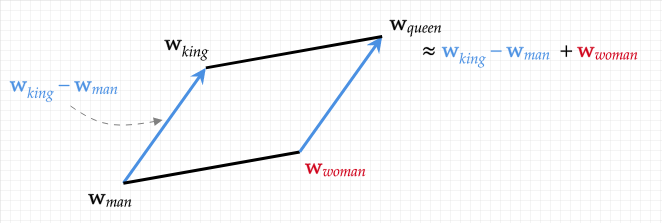
King - man + woman = queen: the hidden algebraic structure of words
Word2vec is a clever algorithm used to create what are called "word embeddings". We can start with some graph paper and start writing out some clusters of words that are related and unrelated. Since our graph paper surface is 2d (2 dimensions; logically, not physically), we can consider that each word has an x,y coordinate pair, and that words that are related are close to each other, while words that are less related are far apart. We'll notice quickly that as we start writing out more than just a few words, we start having difficulty showing the far-ness of some pairs that ended up close together because of their related pairing with another common word.

However, using only 2 dimensions is limiting, so we can use 3, 4, 5, or even 100 dimensions. Since we can't easily envision more than 3-4 dimensions (space and perhaps time), we can imagine that each of these dimensions is a different aspect of meaning of words. Maybe one dimension is related to sweetness, one dimension is related to respect, one or more dimensions are related to color. We don't actually know what they are, as they are automatically "learned" by an algorithm, but this helps us get some feeling of what a "word embedding" is. Elephants and horses might be close together in the "mammal" or "animal type" dimension but far apart in the "size" dimension.
The algorithm works by first assigning a semirandom vector to each word in the training data, where each number is pulled from a random normal distribution centered around 0 with values approximately between -1 and 1. Imagine something like [0.12971, -0.2614, 0.08536, ...]. Since they are random, they don't actually contain any semantic meaning yet. Next, the algorithm runs by comparing proximity relationships between words in training data. This training data can be Shakespeare, emails, books, Wikipedia articles, or anything that contains lots of words and shows usage of those words and the relationships between words. There are multiple ways to look at words that are close to each other, for example checking every pair of words, or every 3 words, or every 5 words, but let's imagine we're looking at every group of 4 consecutive words.
We'll assume our training text data from Wikipedia etc is already cleaned: special characters are removed and the text is broken up into individual words.
The algorithm starts at the beginning of the training text data, looking at the first group of 4 words. If our first sentence is "1 2 3 4 5 6 7 8," then our first group is "1 2 3 4", and then we slide, our second group is "2 3 4 5", third "3 4 5 6", and so on.

Every time we process a group of words like this, we grab the vectors corresponding to those words, and we perform some basic mathematical options to make their vectors closer together. In our 2-dimensional example, imagine that we look at the coordinates for our 4 words on the graph, find the middle point of all of them, and then nudge each one slightly closer to the middle point. We only nudge them slightly, because if we nudge them too close, we'll "overfit" the training. We have lots of training data, so there's no need to forcefully nudge words together the first time we encounter their pairings, as if those words are actually meant to be close to each other, certainly we'll encounter them near each other in many sentences in our training data.
Nudge nudge.
There are all kinds of mathematical tricks to deciding how close to nudge the words together, how many times to train on the training data set, how to initialize the numbers in the vectors at the beginning, and so on, none of which we will concern ourselves with.
Next, we can grab some interesting word out of a dictionary, such as "ocean". Then we can perform some calculations to figure out which other vectors are closest to our "ocean" vector, and we might find similar words that we'd expect to see in the thesaurus: sea, tide, waters. We might even find the names of oceans, things that would be found in the ocean, other large parts of our planet such as "sky" and "Earth". To play with a realtime demo and search, see https://projector.tensorflow.org for an interactive version of the following:
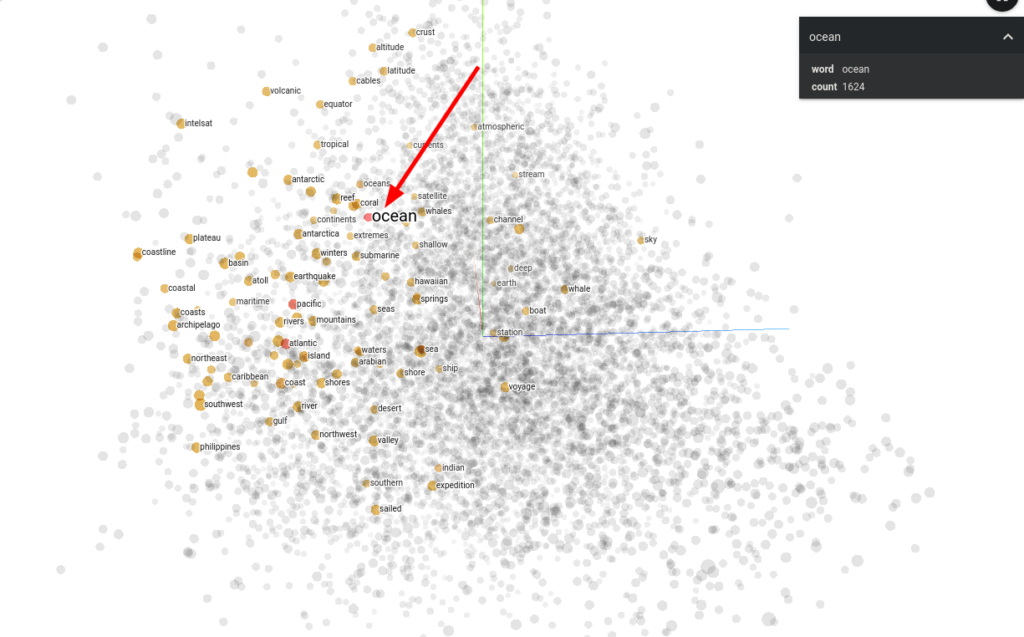
Finally, getting back to the graphic from earlier in this blog post:
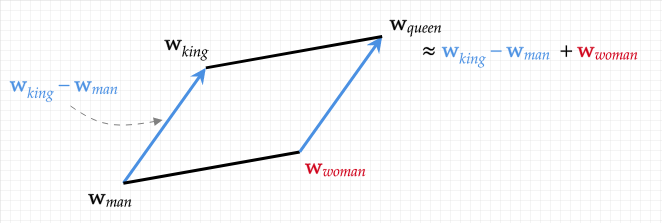
King - man + woman = queen: the hidden algebraic structure of words
After all this training, if we grab the vectors for king, man, and woman, and then we calculate king - man + woman with our vectors, receiving another vector, then compute the real vector that's closest to our calculated vector, what do we find? Queen!!! No one told the Word2Vec algorithm explicitly how these words are related. It learned it through this rather simple algorithm of nudging word vectors closer together based on where they appear in textual data. This "understanding" or meaning that is captured by our vectors is called "semantic meaning".
I want to work us up to understanding ChatGPT, but we're beginning with Word2Vec because I believe it's one of the most miraculous pieces of technology and tools along the many steps it took to get to ChatGPT. Although it's primarily used for word embeddings, it's also been applied to whole documents and dubbed "Doc2vec", and we could also use it for the topics on Wikipedia themselves (think of how all the Wikipedia articles are linking to each other in a complex web), webpages, or anything else that has some sequential relationship. While ChatGPT may not use "Word2Vec" exactly, it similarly uses "embeddings". These embeddings represented as vectors are data that can be operated on quickly in a GPU card by machine learning models, so it's an excellent way to imbue our machines with some kind of understanding about human language.
Thanks for joining us this week and we look forward to next week! We'll be continuing down this machine learning / LLM path for a while as we work our way up to using LLMs locally on your own machine (not in the ChatGPT/etc clouds).