This week we've started with C++ and CMake. While other languages like Rust have an ecosystem for making video games, C++ still seems to be the de facto standard in the game industry. There is a rich history and community in C++ and a variety of open-source projects, and CMake has come a long way in the past 5-10 years alone. While many projects' Make and CMake files are still riddled with ancient blobs of cross-platform madness, 3.0 and several particularly important minor patches since (currently on 3.30) have made it easier to obtain cross-platform support with less effort. There's even a directive that enables you to pull a dependency directly from Github while CMake can handle the depenency seamlessly under the hood so you don't have to. As an example, let's see the FetchContent section of the SFML CMake project template:
include(FetchContent)
FetchContent_Declare(SFML
GIT_REPOSITORY https://github.com/SFML/SFML.git
GIT_TAG 2.6.x
GIT_SHALLOW ON
EXCLUDE_FROM_ALL
SYSTEM)
FetchContent_MakeAvailable(SFML)
The tag can be changed to switch to a different version of SFML with just a few keystrokes. In particular, following their README, we've changed it from 2.6.x to the main branch of SFML which holds sfml3. In fact, 3.0.0-rc.1 was released just today! Another benefit of FetchContent is that you now have the source and can compile the debugging symbols directly so you can step-debug into your dependencies if you need to.
The point of switching over to C++ was to be able to get a better developer experience, providing stronger guarantees about how our code works (otherwise we'd just use Python). For that, we need, at minimum:
- Debugger: GDB
- As much compiler-time checks as you can get your hands on: Clang-Tidy, AddressSanitizer..
- Profiling runtime memory and performance: Valgrind
- Full IDE support: intellisense, go-to-definition, and all of the above integrated to make development as bug-free and smooth as possible (inline compiler checks approximately every time you save to disk).
- Testing framework, i.e. unit testing. We haven't researched into this one yet but I know there's
GTestandCTest.
Using Valgrind+GDB used to be very difficult, but fortunately in 2023 there was official work to directly support using them together. And with a little help from a web search, and a helpful person named Ferran Pujol Camins, we know exactly how to use Valgrind and GDB together in CLion. It might be a little bit tricky to understand (I'm coming from Python, just give me a minute), but a quick overview that might help you understand it more quickly:
- You set up a run/debug target to use
Valgrind, which you configure to startGDBmode immediately when it starts by using--vgdb-error=0. This means that it won't wait for any errors before automatically launching gdb, whereas the default is to wait until a certain number of errors occur before waiting for yourgdbto attach. Then, instead of just hitting the run/play or debug/bug buttons, run one of thevalgrindmodes (coverage/profiler/memcheck) which starts your session and waits for agdbclient to attach. - Configure another run target that starts the
gdbclient and attaches to the already runningvgdbserver. Now your code will stop at your set breakpoints!
Using this method, without even leaving CLion, we can now inspect variables, execution paths, profile, check for memory leaks, and profile overall performance.
When I was originally introduced to IDEs in uni, they were big and scary (or just bloated and unnecessary; I preferred TextMate 2) and I thought I would never understand them, but now that I understand a little bit of the C++/CMake ecosystem that the IDE is trying to abstract away, I see the value of those tools. While we still have to make the CMake file that could end up complex, it's still saving us from a lot of extra typing and messy unmaintainable undebuggable nightmare shell scripts (ugh).
Since I'm starting directly on sfml3 which uses C++17, it will be useful to check the migration guide for good examples of the new correct ways to do things. Since 3.0.0-rc1 was just released today, it appears there is no updated documentation/tutorials for 3.0, but they may be coming soon.
Getting back to CMake, while existing projects may be a mess, new CMake projects can be a lot simpler. There are lots of resources on how to do CMake correctly now. The primary resources I've been using include:
- https://gist.github.com/mbinna/c61dbb39bca0e4fb7d1f73b0d66a4fd1 (lots of handy linked resources)
- https://github.com/dev-cafe/cmake-cookbook A promising
CMakecookbook, it hasn't been updated in a bit but hopefully it shows correct practices - Asking questions and searching how to do things the correct way. Don't just copy from somewhere; look into the ways to accomplish a given goal and figure out which one works better for ease of maintenance and remaining cross-platform. There are a lot of samples out there that are outdated;
CMakehas become easier, so make sure there's not a better way before using something that doesn't look nice.
I'm pleased to continue my foray into the open-source world this week, as I've managed to make an update to the Gentoo wiki (updated a reference to a portage package which moved to a different classification a while ago), and updated SFML's website tutorials to point to the correct minor version documentation when referencing classes.
Game
And finally.. the point of all this is to make a game!!!! So far we're working on the project structure, something similar to the existing Python project but more C++-like with associated namespaces.
We have a machine, and have used the component design pattern in order to separate the responsibility between client and server so the server doesn't need to render sprites and the server can be the source of truth for all clients. And in the case of single-player, the client can potentially (ideally) run the "server" code internally (each machine would run the client and server components simultaneously) and not require to double memory for every machine (and every other object).
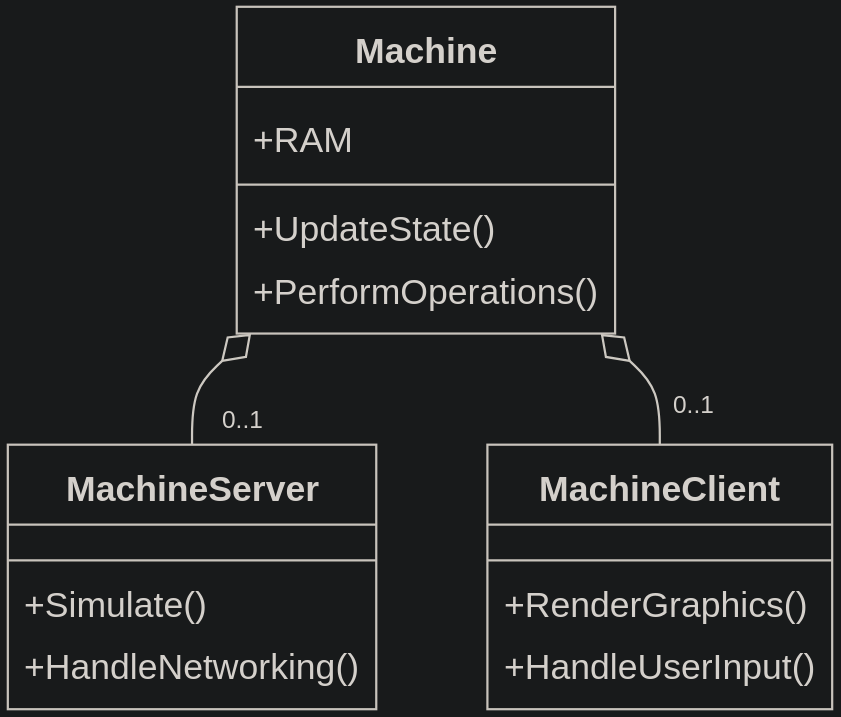
This diagram was generated using the following Mermaid diagram code using their live editor:
classDiagram
class Machine {
+RAM
+UpdateState()
+PerformOperations()
}
class MachineServer {
+Simulate()
+HandleNetworking()
}
class MachineClient {
+RenderGraphics()
+HandleUserInput()
}
Machine o-- "0..1" MachineServer
Machine o-- "0..1" MachineClient
As for the actual implementation of the machine, it may as well just be printing statements to the console! Right now the focus is on general structure that will allow the project to grow without too much pain, and to decide which of the (very few) parts will make it over from Python. Beyond that, we have all the exciting challenges that manual memory management bring in C++ (though RAII is one way to make it much easier and less error-prone), and thus carefully considering the design especially as it relates to memory usage.
Even when I don't know what I'm going to write before I begin aside from a few talking points, I end up with a whole post! Who knew this much stuff is going on in my head! (Weekly meetings in industry were never this awesome.) See you next week!