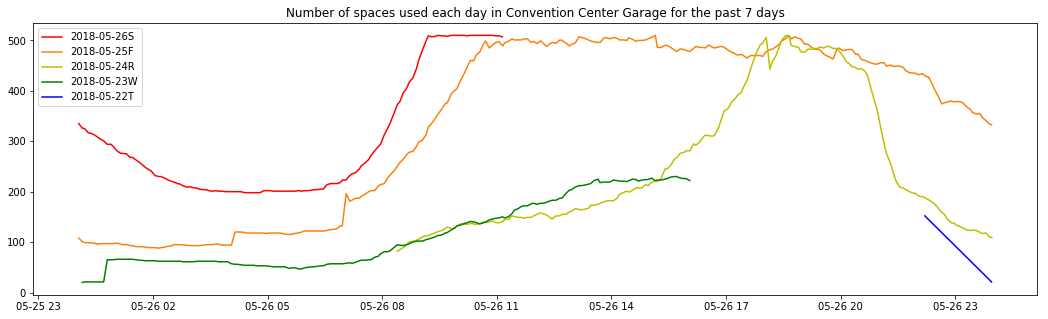
The color scheme follows the same as described in https://violeteldridge.com/2017/11/09/raspberry-pi-plot-of-temperature-humidity-pressure-data/. Roy.G.Biv. (rainbow) with red as today, orange as yesterday, yellow as the day before that, etc.
It can be seen that the parking garage is EXTREMELY FULL, which is due to Fanime in the San Jose Convention Center this Memorial Day Weekend.
Conversely, see this graph, which clearly serves a business district (or otherwise people who work on weekdays):
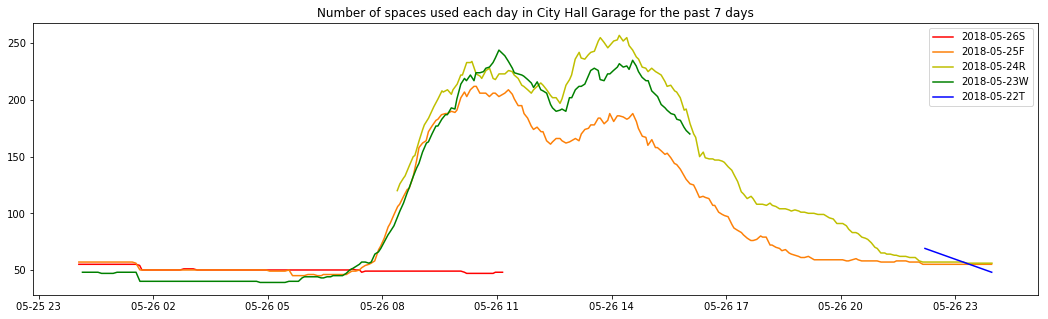
It's completely empty today, Saturday! And the schedule of the weekdays are quite regular, with slightly less cars throughout the day on Friday but still following the general day pattern of the other two recorded weekdays.
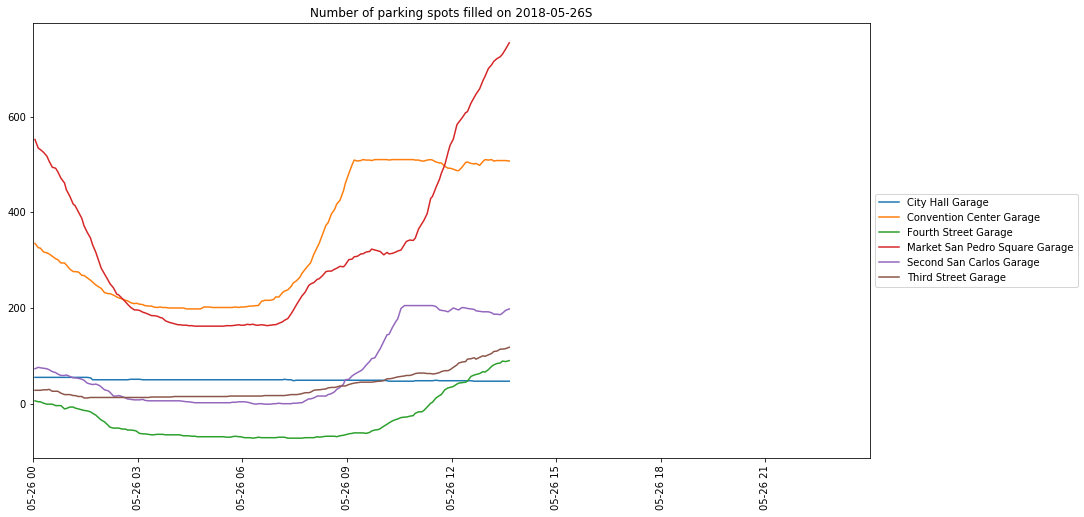
Here, you can see that first the Convention Center Garage filled (notice the plateau), then the Second San Carlos Garage filled, and now people are working on filling the Market San Pedro Square Garage! (However, also note that Fourth Street Garage is reporting usage of a negative number of parking spaces. Since the API returns the number of spaces available in the garage, the data shown here are the number of spaces available in the garage subtracted from the total available capacity of the garage. So this probably means they under-counted the total capacity of the garage, or reported a number of available spaces greater than actual total number of spaces available in the garage.)
I started recording San Jose parking garage data on 2018-05-22. This data is publicly available for free from https://data.sanjoseca.gov/developers/. Here is an example of what the data looks like (json format):
{
"page": "1",
"rows": [
{
"cell": [
"Fourth Street Garage",
"Open",
"324",
"350"
],
"id": "4"
},
{
"cell": [
"City Hall Garage",
"Open",
"255",
"302"
],
"id": "8"
},
{
"cell": [
"Third Street Garage",
"Open",
"142",
"146"
],
"id": "12"
},
{
"cell": [
"Market San Pedro Square Garage",
"Open",
"349",
"425"
],
"id": "16"
},
{
"cell": [
"Convention Center Garage",
"Open",
"445",
"510"
],
"id": "20"
},
{
"cell": [
"Second San Carlos Garage",
"Open",
"184",
"205"
],
"id": "24"
}
],
"total": 7
}